

智能语音语义在产业化方面有哪些应用
根据《2018中国智能语音行业前景研究报告》,2017年中国的智能语音市场规模已经达到了105.71亿元,比2016年增长了70%,而2018年这个规模预计将继续扩大三分之一,达到159.7亿元。
国内的行业规模越来越大,但从技术角度看,目前的智能语音发展到了什么阶段呢?我们先从头开始说。

上世纪50年代到60年代,语音识别研究着眼于单个字词到连续语音的识别,当时最大的困境是对相关数据的计算能力的低下,这直接导致该时期研究进展极其缓慢。到了70年代,计算机性能大幅提升,之前的问题便不复存在,并且随着计算机软硬件技术的高速发展,该研究已不再受困于计算能力,人们便开始将研究重点放在数据算法的优化提升上,并将这一方向保持至今。
简单来讲,这个方向的问题解决方案是基于一个框架,通过对框架内的各部分进行改进,最终向着识别的极限正确率迈进。各部分中,声学模型和语言模型的构建,则是整个方案中的研究焦点。
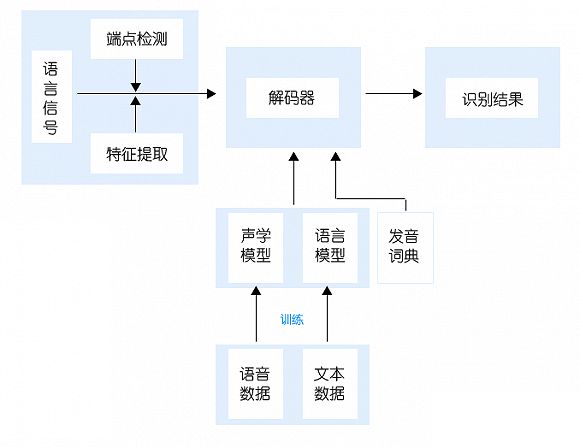
80年代末李开复将隐马尔科夫模型与高斯混合模型(GMM)相结合进行语音识别建模,开发出世界上第一个“非特定人连续语音识别系统”,即SPHINX系统。随后,主流的GMM-HMM技术框架的发展日益稳定,但语音识别效果难以转向应用化的局面长时期没有被打破,这意味着语音识别技术又遇到了瓶颈。
转机出现在2006年。这一年,深度学习的概念被辛顿提出,深度神经网络(Deep Neural Network,DNN)研究因此而复苏。2009年,辛顿和他的学生将深度神经网络应用于语音的声学建模上并获得成功。到了2010年前后,微软研究院的俞栋、邓力等人将深度学习在图像领域的突破移植到语音识别领域,使识别错误率降低了20%以上。从此,基于GMM-HMM的语音识别框架被打破,人们开始转向基于DNN-HMM的语音识别模型的研究。

从2011年到2018年,以深度神经网络为基础的语音识别建模技术迅速发展,语音识别乃至语音交互行业呈现出这样一个现象:全世界范围内的企业的建模技术万变不离“深度神经网络”这一宗,虽大同小异但又各显神通。
技术篇:语音识别和NLP技术仍不成熟
智能语音语义包含语音合成、语音识别和自然语言处理(NLP)三项主要技术。
语音合成技术发展最早,应用已较为普遍,除了合成音仍偏机械之外,基本不存在太大技术问题;语音识别在2012年卷积神经网络(CNN)应用之后,准确率大幅提升,已经在C端、B端得到了广泛应用,但效果和体验还不够理想;NLP技术虽然在搜索引擎中早有应用,但在人机交互领域仍属于浅层处理。
语音识别“鲁棒性“问题显著
在生物学中,有个术语叫做“鲁棒性”,是指系统在扰动或不确定的情况下,仍能保持它的特征行为。这一问题在语音识别领域也存在。
语音识别整个过程包含语音信号处理、静音切除、声学特征提取、模式匹配等多个环节。由于语音信号的多样性和复杂性,系统只能在一定限制条件下才能获得满意效果。在真实使用场景中,考虑到远场、方言、噪音、断句等问题,准确率会大打折扣。目前业内普遍宣称的97%识别准确率,更多的是人工测评结果,只在安静室内的进场识别中才能实现。
要解决语音识别鲁棒性问题,需要在技术和产品两方面进行优化。一方面,在语音增强、麦克风阵列以及说话人分离等多项技术领域持续投入,并结合后端语义,促进对上下文的理解,从而提升识别效果;另一方面,需要从产品设计上进行优化,比如通过进一步交互,使语音识别变得更为准确。
语义分析仍是浅层处理
NLP技术大致包含三个层面:词法分析、句法分析、语义分析,三者之间既递进又相互包含。
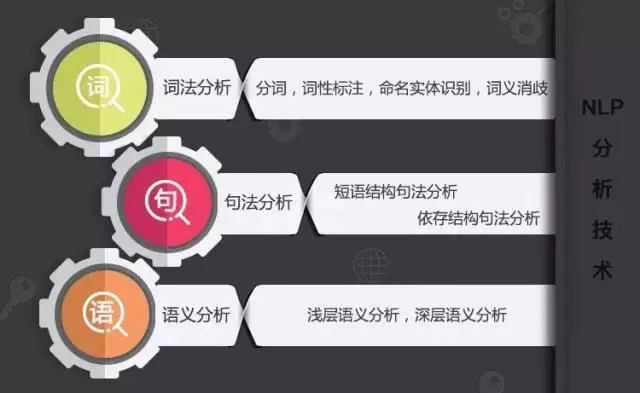
词义消歧是NLP技术的最大瓶颈。机器在切词、标注词性、并识别完后,需要对各个词语进行理解。由于语言中往往一词多义,人在理解时会基于已有知识储备和上下文环境,但机器很难做到。虽然系统会对句子做句法分析,可以在一定程度上帮助机器理解词义和语义,但实际情况并不理想。
目前,机器对句子的理解还只能做到语义角色标注层面,即标出句中的句子成分和主被动关系等,它属于比较成熟的浅层语义分析技术。未来要让机器更好地理解人类语言,并实现自然交互,还是需要依赖深度学习技术,通过大规模的数据训练,让机器不断学习。当然,在实际应用领域中,也可以通过产品设计来减少较为模糊的问答内容,以提升用户体验。
由于人工智能技术对数据依赖性极高,因此,这一领域的技术进步和产业化推进是一种协同关系——通过工程化的方法提升技术效果和体验,从而促进产业化应用,再根据实际应用中的数据和反馈,反过来推动技术实现突破。那么,智能语音语义在产业化方面都有哪些应用领域,又存在哪些问题?
应用篇:C端提升体验,B端提升效率
以问答和聊天为服务形式,智能语音语义在多个使用场景和行业领域都有广泛应用,我们可以简单从C端和B端两个方向分别来看。
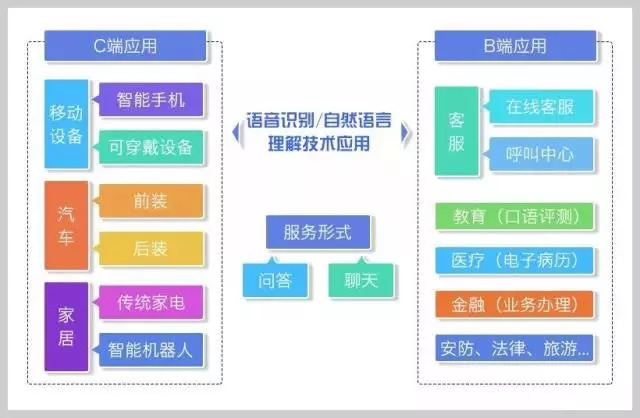
C端应用方面,主要用于移动设备、汽车、家居三大场景,用来变革原有人机交互方式;B端则针对垂直行业需求,提升人工效率,比如帮助医生做电子病历录入,或代替部分人力工作,比如回答大部分简单重复的客服问题。由于两大领域解决的问题不同,因此遇到的挑战也各不相同。
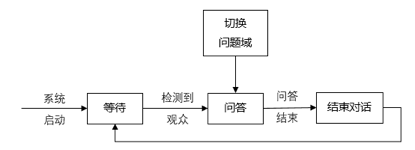
特别地,在智能机器人的应用方面,目前的机器人与用户一般都会采用相互问答的小型对话形式进行交流。为实现上方便,问答对话的领域将被进行合理的限制。
除迎宾和问候语外,一般设计为4个问题域:有关时间、日期和星期的问答,有关全世界各大城市所在时区和当地时间的问答,100以内的数学四则运算题目的问答,没有关系机器人的身世、本领等自身情况的问答。对于每个限定的问题域,相应词汇表的大小是有限的。在限定领域、有限词汇的条件下,机器人基本可以与观众进行自由问答,并可以在不同的问题与之间相互切换。系统工作流程图如下:
来源于:电子发烧友

