基于声学统计模型的HMM参数合成
近年来,基于隐马尔可夫模型(HMM)的语音合成系统得到广泛的重视和应用。与一直以来语音合成方法的主流――基于大语料库的拼接合成方法相比,基于隐马尔可夫模型的TTS系统优势在于系统结构简单,基本不需要任何语言学知识指导系统训练,构建时间短,构建过程基本不需要人工干预,而由于系统属于参数化合成方法,系统的合成结果灵活多变,可以很容易的应用于多个发音人,多种发音风格,多种情感表达的需求中,是嵌入式语音合成或嵌入式TTS技术实现的首选。
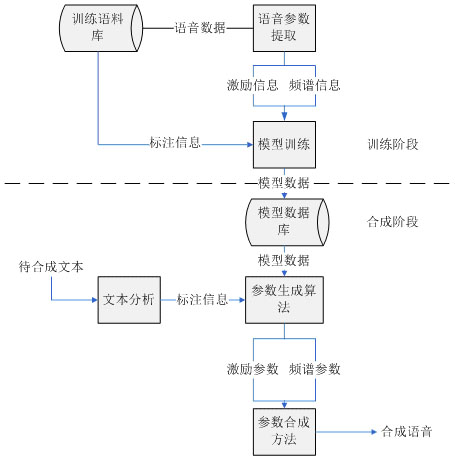
基于HMM的语音合成方法主要分为两个阶段:训练阶段和合成阶段。首先对用于训练的语料进行参数提取(包括频谱参数和基频参数,如LSP线性频谱对参数)。HMM的观察向量可分为谱参数和基频参数两个部分,其中谱参数部分采用连续概率分布HMM进行建模,基频部分采用多空间概率分布HMM(MSD-HMM)进行建模。在合成阶段,首先对给定的待合成文本进行上下文分析,并将文本转换成模型的单元序列。然后根据基于HMM语音合成方法的参数生成算法,同时考虑语音参数的静态参数和动态参数,得到连续的目标语音参数序列,最后通过语音合成器合成出待合成语音。
基于HMM的语音合成方法虽然有系统易小型化、灵活多变等特点,但是和传统的拼接合成相比,还是有音质下降的缺点。传统的拼接合成方法由于是将真实的语音片段通过选音算法拼接在一起所以保留了原始语音片断的音质。而基于HMM的语音合成方法和其他的参数化语音合成方法一样,通过了一次语音编码解码的过程,不可避免的会造成合成音质的下降。另外,在HMM参数估计的过程中的统计方法使得频谱参数趋于平均化;同时,由于模型自身拓扑结构的限制,模型对频谱参数在时域方向变化的描述也存在局限性。这两种在频谱参数层上导致合成语音音质下降的现象本文称之为频域过平滑和时域过平滑。
图1 基于HMM的语音合成方法流程图